Data Structures, Types, and Concepts – CREATE DATABASE dbName; GO

Now it is time to delve a bit deeper into some data concepts. Up to now you may have noticed that the chapter content has been introductory and perhaps not so much about data. In this section, we will focus on data structures, data types, and some general, yet complex, data concepts. You will need to know many of these concepts to pass the exam, and you will see them again in action in later chapters.
Data Structures
Data can be classified in three different ways: structured, semi‐structured, and unstructured. Here you will learn about each one.
Structured
This classification of data arrangement is synonymous with relational data structures. It is found within relational DBMS (RDBMS) systems like SQL Server, MySQL, and Oracle. On Azure, any of the Azure SQL products is where you will find the solution for storing, managing, and analyzing structured data. Figure 2.2 illustrates an example of numerous tables contained within a relational database.
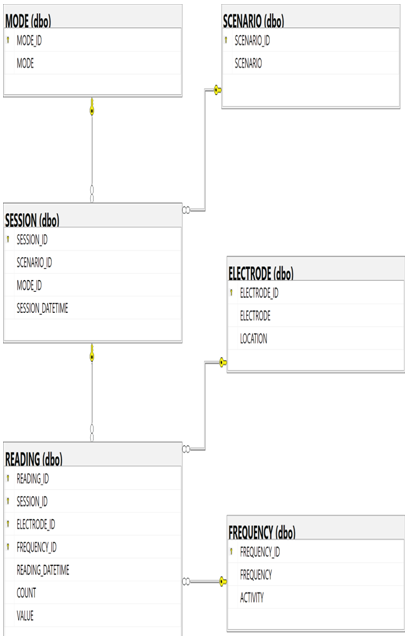
FIGURE 2.2 Tables in a relational database
Notice that there are many relationships between the data in the table that contains a reading from a single electrode of a BCI. The data in the related tables are linked by what is called a foreign key. For example, ELECTRODE_ID, which is the primary key on the ELECTRODE table, is the foreign key on the READING table. This relational structure is helpful in two ways: querying to answer questions and data normalization. With this structure you can query the data to answer any question imaginable. For example, how long did one session take, what is the average value of all ALPHA readings per scenario, or what is the maximum GAMMA value from electrode T8?
Data normalization is most practiced in the context of a relational database. Normal form attempts to maintain data integrity and minimize data redundancy. Data integrity has to do with the usefulness of data over the long term. Over time, data is updated and deleted, and if you are not careful, you can lose the meaning and purpose of the data. One way of maintaining data integrity is to enforce primary and foreign key referential integrity. For example, consider a SCENARIO table that looks like this:
+————–+—————-+
| SCENARIO_ID | SCENARIO |
+————–+—————-+
| 1 | ClassicalMusic |
| 2 | FlipChart |
| 3 | Meditation |
+————–+—————-+
SCENARIO_ID is the primary key for this table and is used as part of the foreign key on the SESSION table. If the SCENARIO_ID of 1 is added to the SESSION table, this means you would no longer be able to delete that row with a primary key of 1 from the SCENARIO table. This is because there is now a referential integrity constraint between the SCENARIO and the SESSION table. Imagine if you were able to delete the SCENARIO row with the primary key of 1. If, after you deleted it, you wanted to check which scenario the SESSION was linked to, it would no longer be possible since the value of 1 is included in the SESSION table instead of ClassicalMusic. Essentially, without knowing the scenario in which it was collected, the data is worthless.
An alternative to creating relationships between numerous tables and building relationships between them is to simply create a single table. You could then dump all the data into that table. The table would very likely end up with a huge number of columns and a large amount of redundant data. Consider the fact that it would be expected to have numerous sessions for each type of scenario. If you placed all that data into a single table, you would end up with having ClassicalMusic, FlipChart, Meditation, and so forth duplicated many times in the Scenario column instead of a single numeric value. This results in less space and less duplication of the same data, even if it is not useful.
To get some better insights and experience with a relational database, complete Exercise 2.1, where you create an Azure SQL database and tables and load it with data.
Now it is time to delve a bit deeper into some data concepts. Up to now you may have noticed that the chapter content has been introductory and perhaps not so much about data. In this section, we will focus on data structures, data types, and some general, yet complex, data concepts. You will need…
